In Tracy Kidder’s classic chronicle “The Soul of a New Machine”, Tom West is directing the last-ditch engineering effort behind a new computer for Data General Corporation, against an impossible deadline.
Tom and his engineers are worried that there is a bogeyman hiding inside their new machine.
The bogeyman is some overlooked, yet fatal design error that may require scraping months of work. This would certainly doom the project, damage Tom’s career at Data General, and very likely sink the company itself. Thanks to Moore’s law, Data General is pushing the limits of complexity with their new 32-bit design. Despite years of experience building much simpler computers, senior engineers find themselves ill-equipped for the new order of challenges presented by the new machine. The effort requires entirely new processes and entirely new tools.
When they get overwhelmed by uncertainty, they can’t help but think of the bogeyman, “just something dark and nameless. That the machine just won’t ever work.”
Forty years later, we’re still pushing the limits of complexity—now with software instead of hardware. Today’s products are powered by untold layers of abstraction and intricate meshes of microservices. System scalability is our new bogeyman, who quite literally haunts us at night by making our phones go off with alerts caused by sudden service degradations and full-on outages.
On paper, keeping this new bogeyman in check seems straightforward.
Business executives should always ask what sort of growth their business can handle and at what cost. Engineers should always inspect their systems for scalability errors that will cause outages and require dangerous rewrites.
And yet, time and time again, and often in spite of seemingly unlimited resources, we find ourselves ill-equipped to treat the problem of system scalability with confidence. We fall asleep fully aware of the bogeyman, who had made himself at home.
Why is that?
To help us understand, let us try to define some obvious scalability characteristics of a typical business system whose aim is to grow as big as possible. There will always be an axis representing the number of users, devices, data, or any other key metric aligned with growth. Let’s call this axis success. As success increases, we measure the associated operational cost and quality.
Let’s see how this relationship may look in a business that sells subscriptions for software that customers download and install on their computers (e.g. sheet music editor).

Both lines are flat! This business has a constant (and likely very low) operational cost of providing downloads, coupled with license enforcement. Quality also remains constant—each instance of the software works exactly the same, regardless of the number of users. Companies that enjoy this kind of scalability are few and far between.
Now, let us see how this translates to a business that requires a backend service.
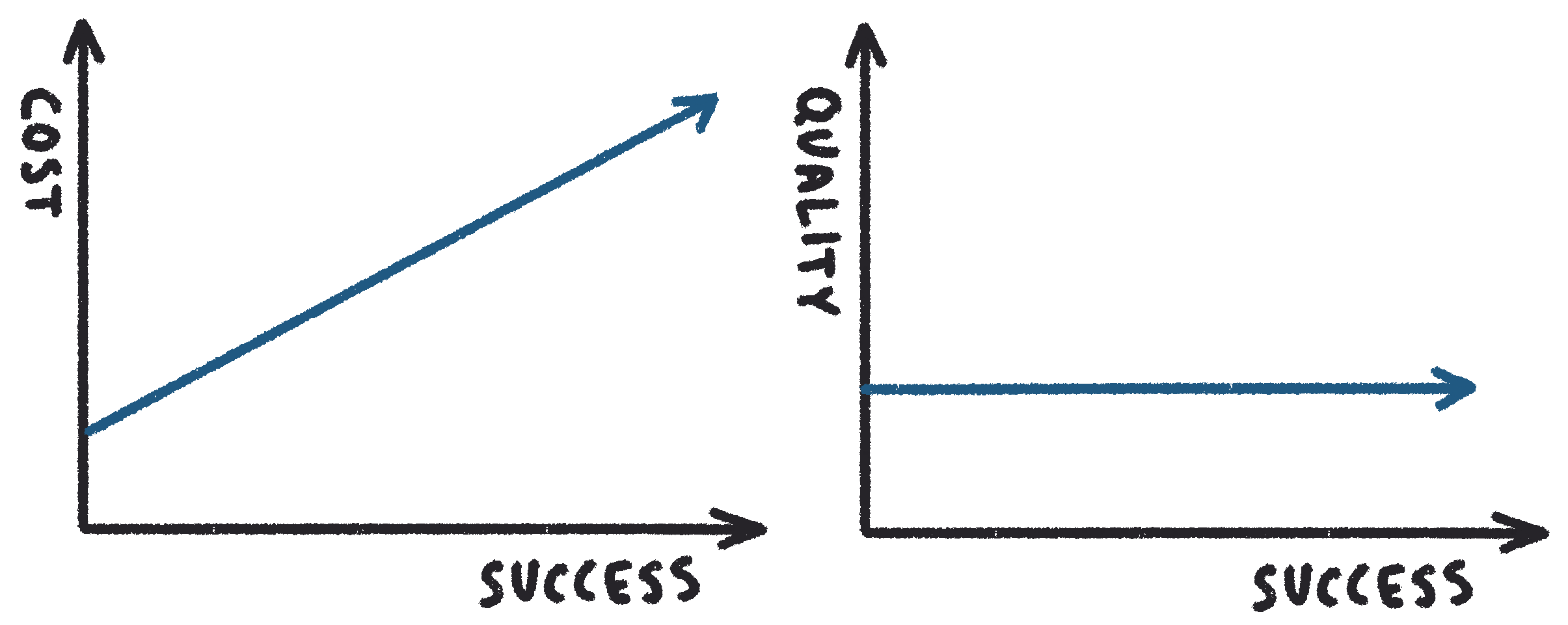
Here, operational cost is a linear function of success—increase in success is proportionally reflected by the increase in operational cost. Quality remains constant—increase in cost is covering the capacity necessary to maintain constant (good) user experience. In an ideal world, these two lines continue straight, until we have captured the entire market.
The real world comes with a bogeyman.

The bogeyman is an inflection point uncovered by some unaccounted-for scalability limit.
Our first reaction is to try and shoo the bogeyman away by increasing hardware capacity. This doesn’t help for long, since after we have reached the inflection point, our system either stops working altogether, or adds a steep exponent to its cost function. Once we run out of capacity, quality drops. Our service gets overloaded and suffers a partial or complete outage.
(This picture can become more complicated for a system that is compartmentalized. For example, a SaaS backend can have separate scalability characteristics with respect to the total number of organizations using the service, and the maximum number of users within each organization.)
To reiterate, the problem above is not so much with the fact that our system turned out to have a limit, as all systems do, but with the fact that when our system hit its inflection point, it came to us as a surprise.
The inflection point may have been caused by a missing database index. Or, perhaps, it was the transaction-per-second limit of a centralized database instance that we kept upgrading until it reached maximum instance size. It could have been the limit of our networking infrastructure that became overloaded by the number of nodes communicating over a chatty protocol. Or, maybe, it was the computational limit of a key algorithm we use to process data.
Point being, the cure for a scalability problem could be a quick fix—add an index, break up a cluster—or some fundamental mathematical ceiling in computer science. Either way, when the bogeyman shows up unexpectedly, it hurts. Just as we are finally riding the wave of success straight to our big reward ceremony, we trip and fall face-first onto the red carpet, while getting out of the limo. In front of everyone.
Enter scalability testing.
Scalability testing is a process of ascertaining the scalability characteristics of a system.
Scalability stress testing answers the question of whether the system can handle a given workload (number of users, devices, amount of data, etc) with what quality (latency, rate of errors, etc) and at what cost.
Scalability limit testing finds the scalability limit of a system by continuously adding capacity and increasing workload until the system breaks down.
When this limit is found, scalability analysis is used to determine the root cause of the limit by using telemetry data collected during the test.
Multiple limits at different capacity and workloads levels are likely—when one is found and fixed, we keep looking.
Scalability testing can and should be a part of overall testing strategy, along with unit, functional, and acceptance testing—today more so than ever, because it’s a brave new world out there. Consider:
- It used to be feasible to estimate the scalability limit of an entire system by looking at the specifications of a single underlying database system. If, say, your RDBMS could handle a certain number of transactions per second, this would directly translate to the number of users with known load patterns. Today, it’s not this simple. Modern systems use multiple databases, caches, and message queues that can both improve scalability and introduce unexpected limitations.
- Workload is less predictable with global consumer and SaaS companies experiencing viral and seasonal cycles. Today, infrastructure is expected to scale with demand.
It is also becoming easier to run scalability tests at production scale.
- On-demand cloud infrastructure makes it economically feasible to run scalability tests by temporarily provisioning multiples of production capacity, along with corresponding load farms.
- With tools like CloudFormation, Cloud Deployment Manager, and Terraform, it is easy to stand up and tear down full replicas of production infrastructure.
To boot, making stress testing a part of a Continuous Integration Pipeline (CI) brings sanity to software development where it matters most.
- We gain confidence in our production system’s ability to handle stress workloads. Stress workloads must always be larger than the current production load, to account for projected business growth.
- We can quickly find major scalability bugs by reviewing failed stress test results.
- We can find minor scalability bugs that emerge after seemingly minor code changes, by observing changes in quality metrics such as CPU load, latency, throughput, and error rate.
In addition to continuous stress tests, it is worthwhile to perform limit testing before each major release. This helps us understand near-future risks and plan accordingly, as our business continues to grow and our stress workload get closer to the current actual limit workload.
Scalability testing makes the bogeyman disappear by becoming a known entity. It’s on our calendar, we have made an appointment. We know when to expect it, and we often know what needs to be done to have it skip our house altogether and try the competitor’s door instead. We now have known headroom for business growth, which may translate into more aggressive marketing and customer acquisition. We are confident in the operational costs of running the business, which translates to better projections of margins. We sleep better, too.