While evaluating the performance of a server application, we eventually (and hopefully) run up against the most fundamental constraining factor: the network.
Cloud providers tend to offer somewhat handwavy guidance on networking constraints, especially when compared to the exhaustive literature explaining the quotas for RAM, CPU, and I/O.
While working on an unrelated stress test in EC2, we were surprised by some results that led us down the path of investigating EC2 network capacity claims, resulting in this writeup.
Bandwidth, you say?
EC2 documentation describes network performance in terms of maximum available bandwidth. Instances using Enhanced Networking can have bandwidth up to 25 Gbit/s. This is great news for a video streaming service, but what does this maximum bandwidth mean for a transactional application, such as an HTTP server? Do we add up all payload and protocol overhead to see if fits the bandwidth budget?
To answer this question, we have to look at how lower level protocols—like TCP and IP—handle HTTP transactions.
Since HTTP (version 1 and 2) requires a reliable connection between the client and the server, it depends on TCP to provide an illusion of a continuous, bi-directional data stream. TCP does this by breaking messages into packets and resending those not acknowledged in time. TCP itself relies on IP for best-effort routing of packets to the destination.
How many TCP/IP packets does it take to process one HTTP transaction on an established TCP connection?
First, the client sends a request packet. Then, the server replies with an ACK packet, confirming delivery. Next, the server sends a response packet. Finally, the client replies with an ACK packet, confirming receipt. If either the request or the response is larger than the maximum IP packet size, it will be split into a series of packets. The maximum packet size, or MTU, is defined by the smallest maximum packet size of all the underlying networks the packet will encounter along its route. In the case of internal EC2 network, the MTU is 9001 bytes. If HTTP requests and responses stay within this MTU limit (minus protocol overhead), each HTTP transaction takes exactly four packets.
The question is, what sort of packet-per-second performance can we expect from EC2? We found very little information in the documentation, so we decided to find out.
Discarding packets
To avoid having to deal with the complexities of TCP in our analysis, we decided to run our experiments with UDP. UDP is a thin layer on top of IP, with exactly the same semantics: unreliable, one-way delivery of datagrams.
We first had to extend the Stressgrid load-testing framework to support UDP. We were then able to apply a continuous payload of 100 random bytes with a 100±5% millisecond interval, using the following Elixir script:
payload = payload(100)
0..1000000000000 |> Enum.each(fn _ ->
send(payload)
delay(100, 0.05)
end)
When a server receives a UDP datagram on a port with no application listening, the datagram gets discarded. This discarding is extremely efficient, and yet perfectly observable. By using sar, we can easily measure how many packets per second get dropped with the noport/s metric:
sar -n UDP 1
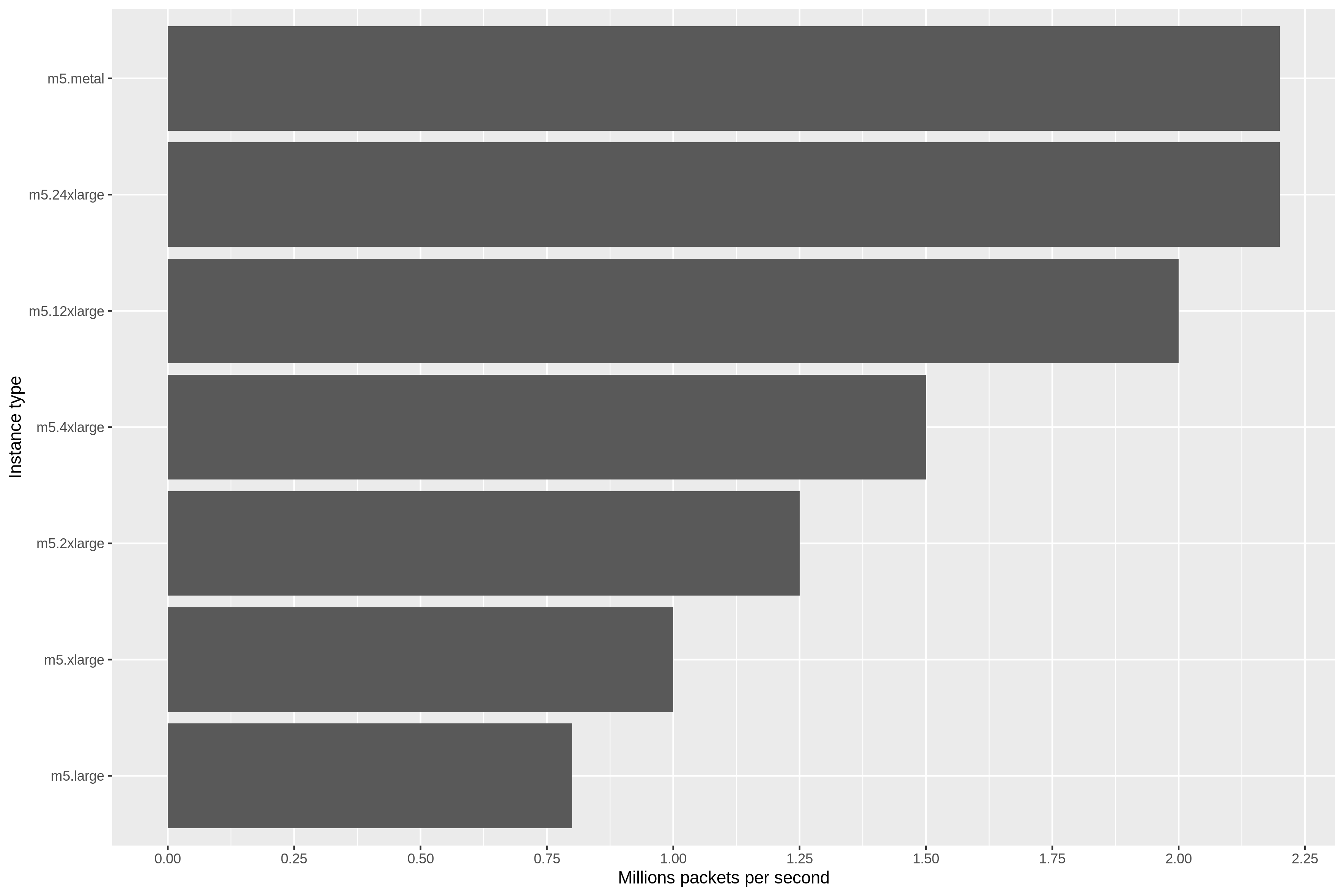
For our first experiment, we produced a flood of 4 million packets per second from 100 Stressgrid generators, with the load gradually increasing over a 10-minute period. We used small packets with 100 bytes of payload to make sure we don’t approach bandwidth limits.
We then measured how many packets reached our EC2 instances to get discarded. We tested against all available instance types of class m5. All were running Amazon Linux 2, with Enhanced Networking enabled.
The results clearly suggest the existence of packet-per-second throttling, with quota increasing with instance size.
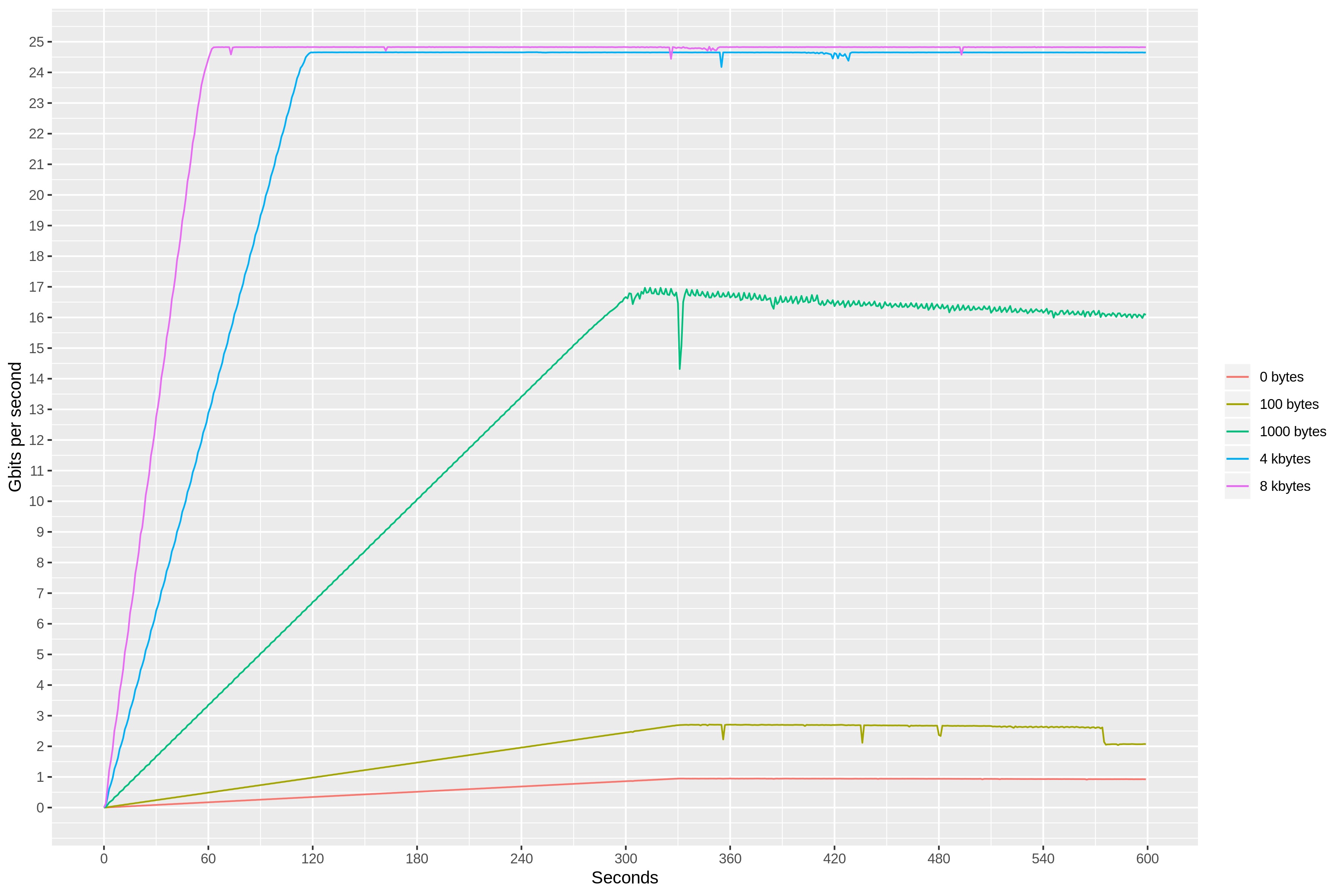
For the second experiment, we decided to vary the size of our packets payload between 0 and 8 kbytes, with the goal of testing bandwidth limits as well. We ran this load against an m5.metal instance with a 25 Gbit/s bandwidth limit.
It appears that 4- and 8-kbyte packets saturate the available bandwidth, failing to reach the packet-per-second rate observed with smaller packets.

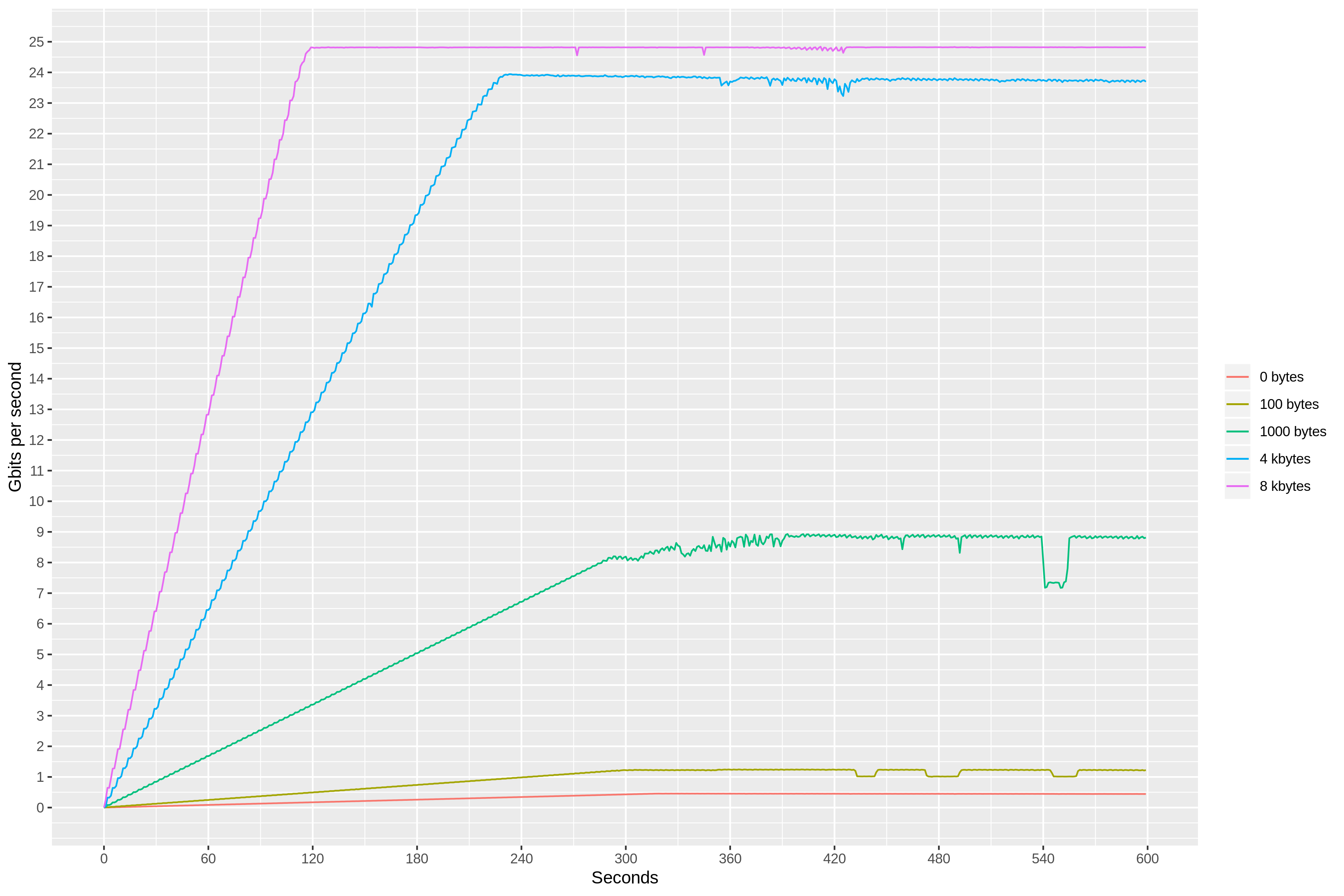
By plotting the data rate after accounting for UDP, IPv4, and Ethernet overhead, we can see that we have indeed reached the rate of 25 Gbit/s for large packets.
Simple server
In the two experiments above, we measured how many packets per second we could send through our network.
Next, we wanted to see if the operating system kernel can successfully deliver the packets to a userland application and back to the network, when subjected to our stress load.
To test this, we built a simple UDP server in C. All this server does is echo each packet it receives back to the sender. To allow multiple threads to handle the packets as quickly as possible, we used the SO_REUSEPORT socket option and started one thread per CPU, each with its own socket.
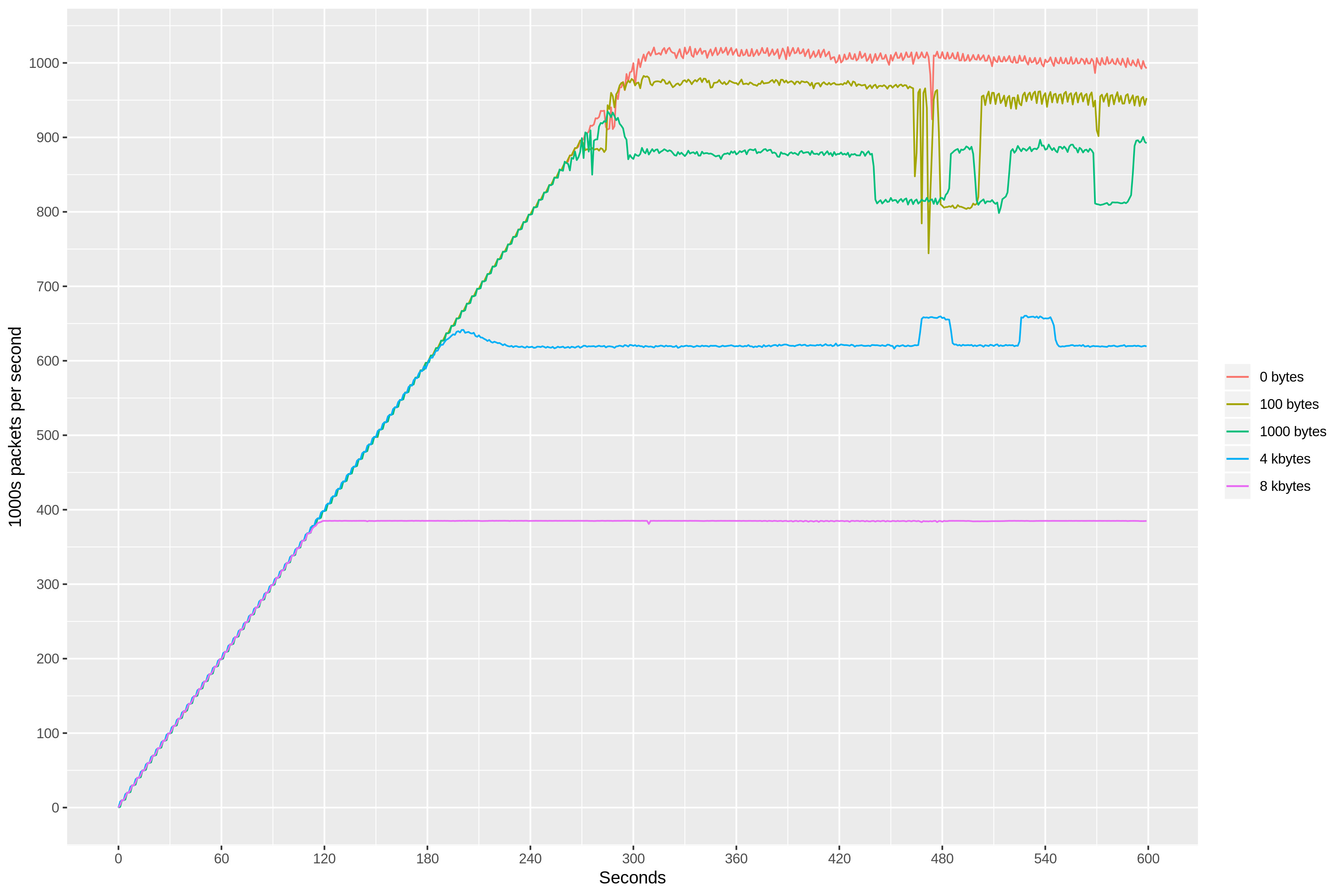
Like in our last experiment, the stress load consisted of variable-size packets, ranging between 100 bytes and 8 kbytes. We ran this test against the m5.metal instance where we previously observed the “budget” of 2.2M packets per second. We used sar to collect inbound packet rate metric (idgm/s), while observing similar values for the outbound packet rate (odgm/s). By ensuring that UDP errors (idgmerr/s) remained at zero, we knew that our server was able to keep up with the inbound packet rate. The results were surprising!
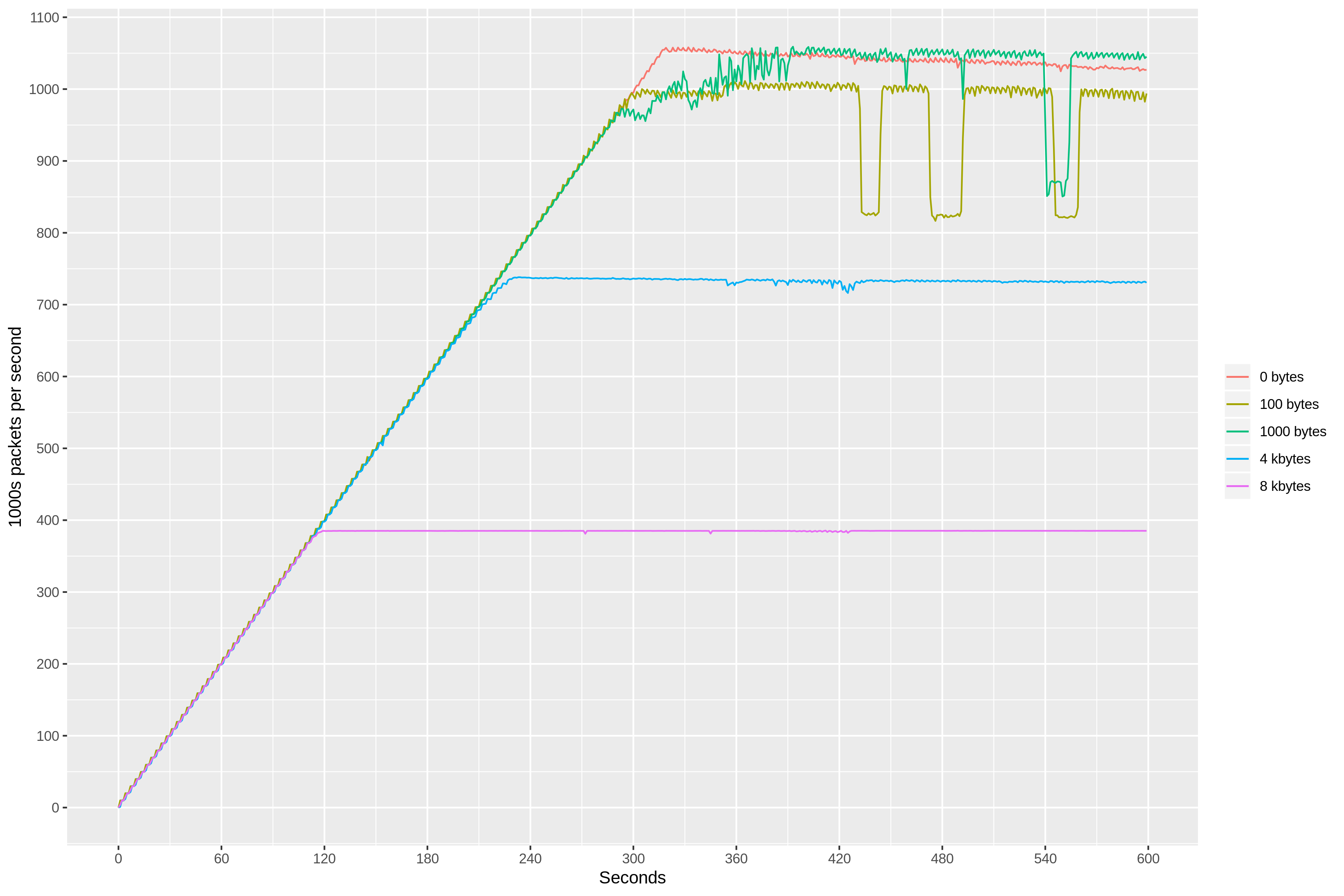
We can see that the packet-per-second budget is split between both inbound and outbound traffic. And, since we try to match every inbound packet with an outbound echo packet, our UDP server can only process at most 1 million echoes per second. The bandwidth limit, on the other hand, applies to each direction independently, with inbound data rate still reaching 25 Gbit/s.
In our last experiment, we wanted to see whether adding multiple network interfaces changes the packet-per-second and bandwidth limits in any way.
To do this, we extended the Stressgrid load-testing framework with the ability to load-balance the workload across multiple target IP addresses in a simple round-robin fashion.

It turns out, there is an small decrease in performance for all packet sizes, except 8 kbytes. This suggests that our instance uses a single physical interface multiplexed across several logical ones.
Conclusion
By running these experiments, we determined that each EC2 instance type has a packet-per-second budget. Surprisingly, this budget goes toward the total of incoming and outgoing packets. Even more surprisingly, the same budget gets split between multiple network interfaces, with some additional performance penalty. This last result informs against using multiple network interfaces when tuning the system for higher networking performance.
The maximum budget for m5.metal and m5.24xlarge is 2.2M packets per second. Given that each HTTP transaction takes at least four packets, we can translate this to a maximum of 550k requests per second on the largest m5 instance with Enhanced Networking enabled.