Both HTTP 1.x and HTTP/2 rely on lower level connection-oriented protocols, namely TCP/IP and TLS. These protocols provide reliable delivery and correct order when data is chunked into multiple packets. TLS also includes encryption and authentication.
The HTTP client needs to open a connection before it can send a request. For efficiency, each connection is likely to be reused for sending subsequent requests. To ensure this is the case while using HTTP 1.0, the client can set the connection: keep-alive header, while HTTP 1.1 and HTTP/2 keep connections alive by default.
Web browsers maintain “warm” connections for a few minutes, and server-to-server connections are usually kept alive much longer. The WebSocket protocol (built on top of HTTP) only allows for explicit closure of underlying HTTP connections.
What this means, performance-wise, is that measuring requests per second gets a lot more attention than connections per second. Usually, the latter can be one or two orders of magnitude lower than the former. Correspondingly, benchmarks use long-living connections to simulate multiple requests from the same device.
However, there are scenarios where this assumption does not hold true. For example, low-power IoT devices cannot afford to maintain active connections. A sensor could “wake up”, then establish a connection to a server, send a payload request, receive an acknowledgment response, close the connection, and go back to “sleep”. With such a workload, the connection-per-second and request-per-second rates would be the same.
In this article, we look at scaling Elixir to handle 100k connections per second.
The workload consists of 100k devices, each simply opening a TCP/IP connection, waiting for 1±5% seconds, and closing the connection. The test consists of three phases: a 15-minute rampup, 1 minute sustained load, and 15-minute rampdown. The following Stressgrid script represents the workload:
delay(1000, 0.05)
We tested against Ranch, which is the socket acceptor pool at the heart of the Cowboy web server. With Ranch, it is possible to implement a server for any TCP/IP- and TSL-based protocol, which makes our benchmark not specific to HTTP. We used Ubuntu 18.04 with the 4.15.0-1031-aws kernel, with sysctld overrides seen in our /etc/sysctl.d/10-dummy.conf. We used Erlang 21.2.6-1 on a 36-core c5.9xlarge instance.
To run this test, we used Stressgrid with twenty c5.xlarge generators.
Ranch 1.7
In the first test, we used unmodified Ranch 1.7. The connection rate graph shows a clear breaking point at 70k connections per second. After this point, connection latency grows, causing the rate to peak at 82k connections per second.

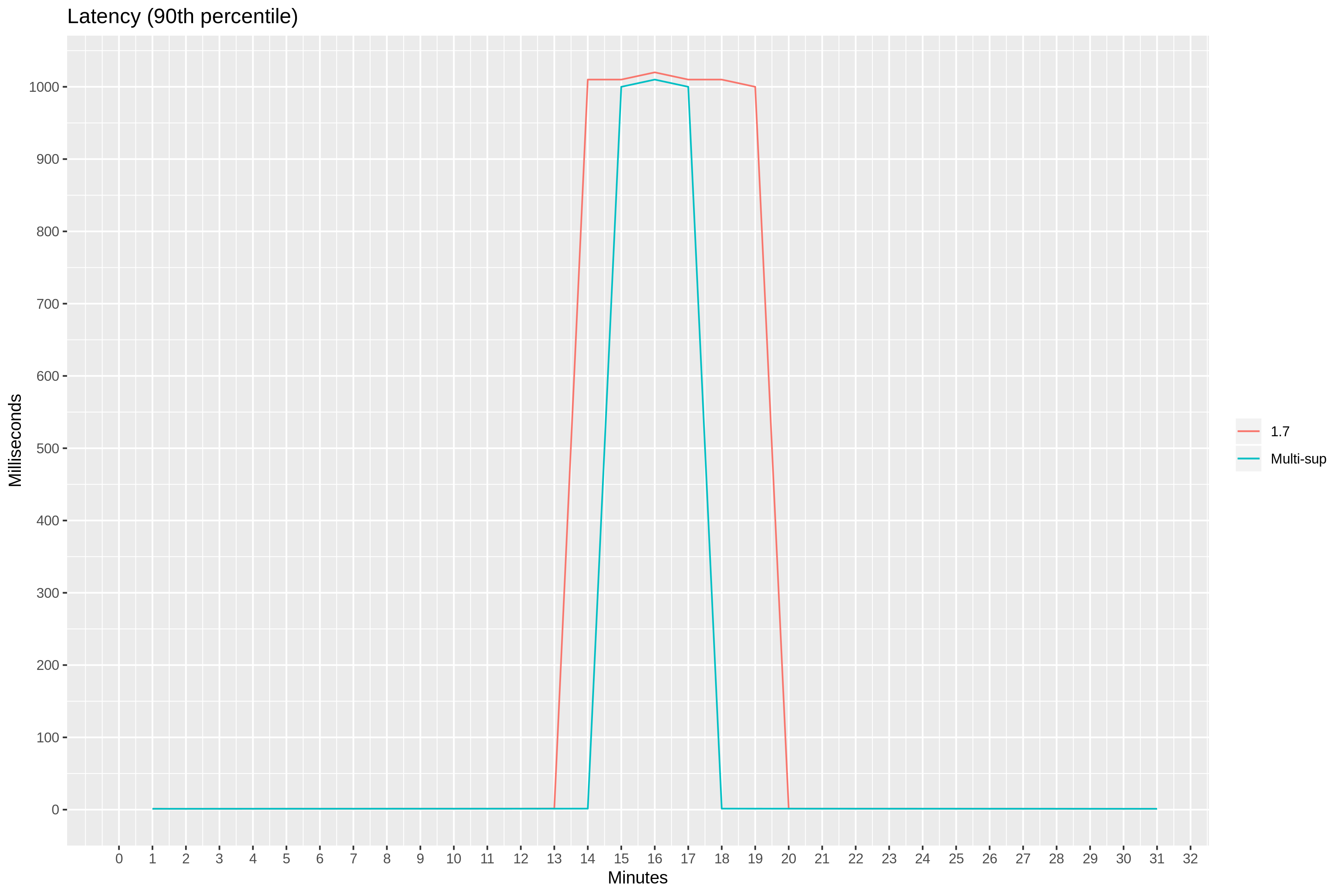
Another good way of observing the bottleneck effect is the 90th percentile latency. At 14th minute mark, the latency jumps from single-digit milliseconds to 1 second.

To understand this bottleneck, we need to take a quick dive into the architecture of Ranch.
Ranch maintains a pool of acceptors to enable more throughput when handling new connections. By default, Ranch starts with 10 acceptors. In this test, we set it to 36—the number of CPU cores on our c5.9xlarge. We also performed the same test with acceptors set to 4x and 16x number of CPU cores, with negligible differences.
This behavior makes it possible for our server to accept new connections with a high degree of parallelism. When a socket is accepted, it is passed to to a newly-started connection process. However, all connection processes are started by a single connection supervisor. This supervisor becomes our primary suspect in our search for the bottleneck.
To test this theory, we modified our test server to report the supervisor’s message queue length. Indeed, we observed between 20 and 200 messages in the 90th percentile, starting at 9th minute mark.
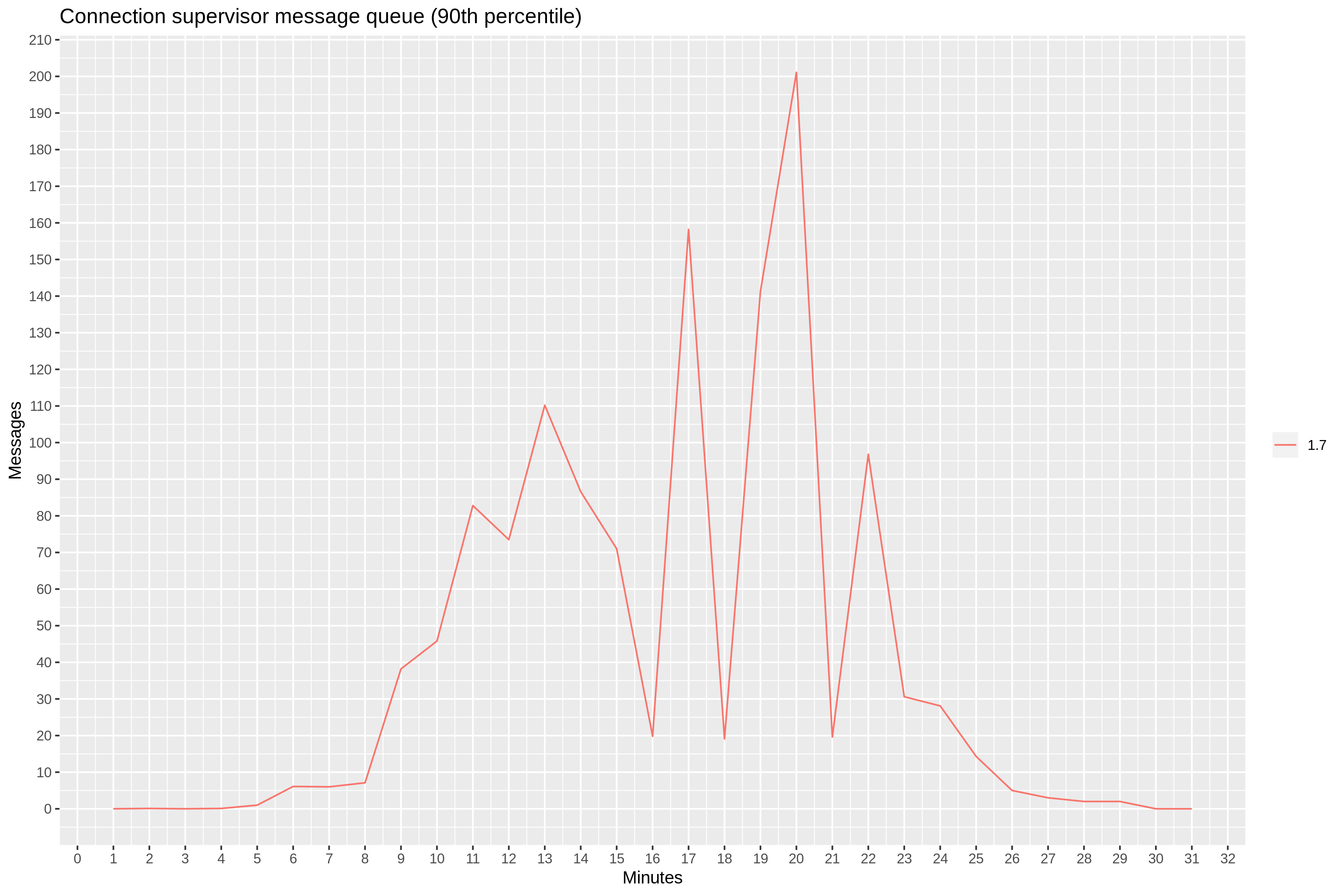
The good news is that Ranch maintainers are well aware of this problem. There is a pull request with a proof of concept that introduces acceptor-supervisor pairs.
Multi-supervisor Ranch
With acceptor-supervisor pairs, there should no longer be any points of contention in the path of creating new connections within Ranch. To verify this, we collected a similar report for the total message queue length for all 36 connection supervisors. The 90th percentile now stays below 3.
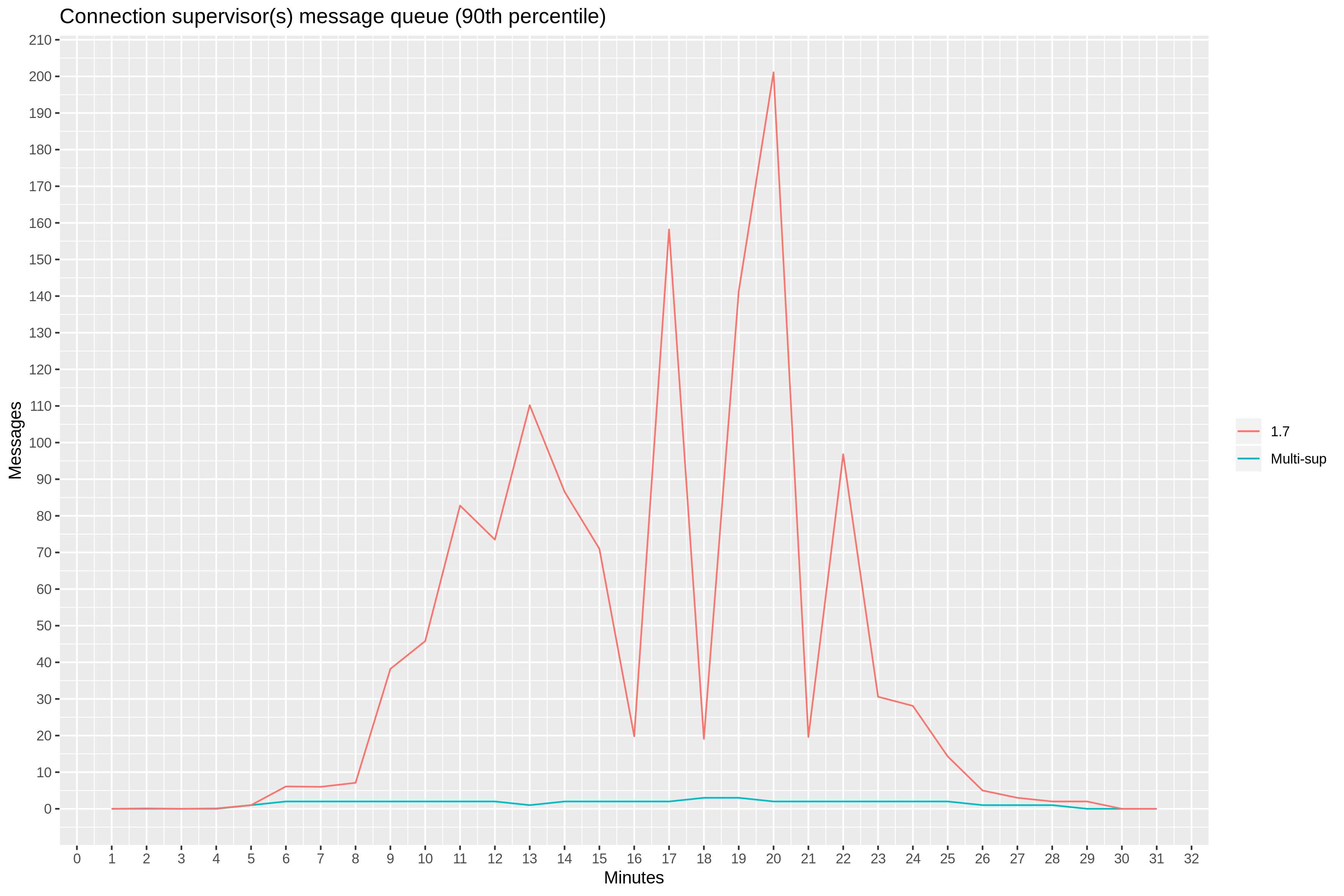
But is it too early to celebrate—at 15th minute mark, 90th percentile latency jumps to 1 second again.
The breaking point in the connection rate graph is less pronounced, but remains at about 70k connections per second.
We hit another bottleneck.

To understand this bottleneck, we need to understand how TCP/IP is implemented inside the Linux kernel.
When the client wants to establish a new connection, it sends a SYN packet. When the server receives SYN, it places the new connection in SYN queue and reports it as being in a syn-recv state. The connection stays in syn-recv state until it is moved to the accept queue. When the userland program—in our case Ranch—invokes the accept() function, it removes the connection from the accept queue, and the connection becomes established. Cloudflare has a blog post with a detailed explanation of this mechanism.
We created a bash script that records the number of connections in syn-recv state during our test.
Around 11th minute, the number of connections quickly reaches 1k. With the maximum SYN queue length set to 1024 with the net.core.somaxconn sysctl parameter, overflowing SYN packets get dropped. The clients back off and re-send SYN packets later. This results in the 90th percentile latency we saw earlier.

Modified Ranch is able to accept with higher degree of parallelism, but the accept() function gets invoked on a single shared listener socket. It turns out, the Linux kernel experiences contention when it comes to invoking accept() on the same listener socket.
In 2010, a group of engineers from Google discussed the issues with lock contention and suboptimal load balancing in a presentation, where they also estimate the maximum connections per second rate to be around 50k (on 2010 hardware). Furthermore, they proposed a Linux kernel patch that introduced the SO_REUSEPORT socket option, that makes it possible to open many listener sockets on the same port, causing the sockets to be load-balanced when accepting new connections.
Multi-supervisor Ranch with SO_REUSEPORT
To find out if the SO_REUSEPORT socket option would help, we created a proof of concept application in which we ran multiple Ranch listeners on the same port with SO_REUSEPORT set using the raw setops option. We set the number of listeners to be the same as the number of available CPUs.
With this proof of concept, we again measured the number of connections in syn-recv state during our test. This number never gets close to 1k, meaning we’re no longer dropping SYN messages.
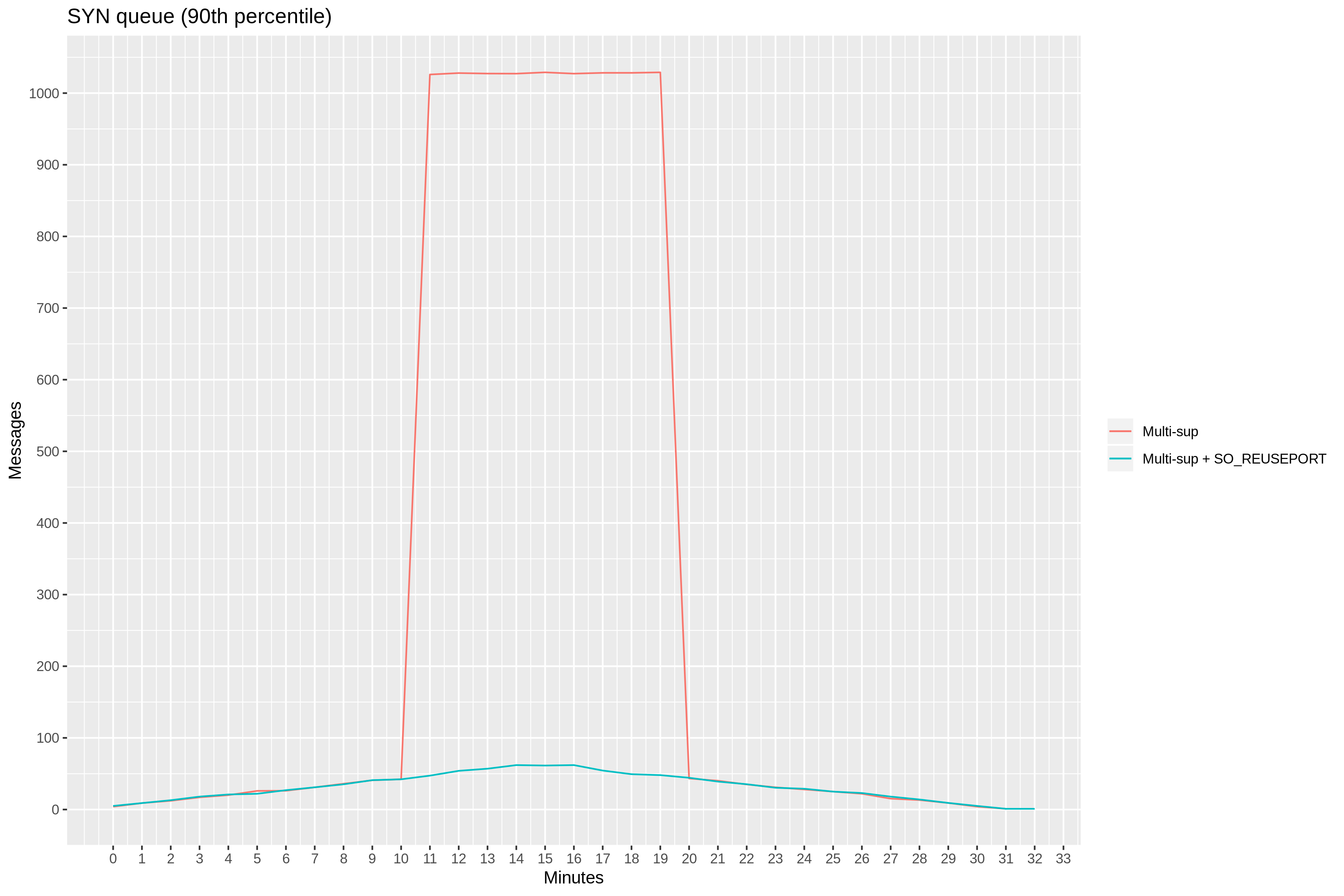
90th percentile latency confirms our findings: it remains consistently low throughout the test.

When zooming in, 90th percentile latency measures between 1 and 2 milliseconds.

We also observed much better CPU utilization, which resulted from less contention and fairer load balancing when accepting new connections.

Finally, the connections per second rate reaches 99k, with network latency and available CPU resources contributing to the next bottleneck.

Conclusion
By analyzing the initial test results, proposing a theory, and confirming it by measuring against modified software, we were able to find two bottlenecks on the way to getting to 100k connections per second with Elixir and Ranch. The combination of multiple connection supervisors in Ranch and multiple listener sockets in the Linux kernel is necessary to achieve full utilization of the 36-core machine under the target workload.