While benchmarking Go vs Elixir vs Node, we discovered that Elixir (running on the BEAM virtual machine) had much higher CPU usage than Go, and yet its responsiveness remained excellent. Some of our readers suggested that busy waiting may be responsible for this behavior.
Turns out, busy waiting in BEAM is an optimization that ensures maximum responsiveness.
In essence, when waiting for a certain event, the virtual machine first enters a CPU-intensive tight loop, where it continuously checks to see if the event in question has occurred.
The standard way of handling this is to let the operating system kernel manage synchronization in such a way that, while waiting for an event, other threads get the opportunity to run. However, if the event in question happens immediately after entering the waiting state, this coordination with the kernel can be wasteful.
An interesting side effect of the busy wait approach is that CPU utilization reported by the operating system becomes misleading. Since kernel waiting (even if implemented as busy waiting) does not figure in CPU utilization results, busy waiting of the BEAM certainly does.
To confirm the theory of BEAM busy waiting contributing to high CPU utilization in our benchmarking test, we re-ran the test with a modified virtual machine.
The modification was to enable extra microstate accounting by running ./configure on our build with the --with-microstate-accounting=extra parameter. We then used msacc to collect microstate accounting during the 10 minutes of the sustained phase of the 100k connections test, on a c5.9xlarge AWS instance.
Average thread real-time : 600000658 us
Accumulated system run-time : 21254177063 us
Average scheduler run-time : 586759264 us
Thread alloc aux bifbusy_wait check_io
async 0.00% 0.00% 0.00% 0.00% 0.00%
aux 0.02% 0.06% 0.00% 0.00% 0.02%
dirty_cpu_sche 0.00% 0.00% 0.00% 0.00% 0.00%
dirty_io_sched 0.00% 0.00% 0.00% 0.00% 0.00%
poll 1.99% 0.00% 0.00% 0.00% 19.50%
scheduler 4.89% 2.63% 6.41% 56.28% 2.82%
Thread emulator ets gc gc_full nif
async 0.00% 0.00% 0.00% 0.00% 0.00%
aux 0.00% 0.00% 0.00% 0.00% 0.00%
dirty_cpu_sche 0.00% 0.00% 0.00% 0.00% 0.00%
dirty_io_sched 0.00% 0.00% 0.00% 0.00% 0.00%
poll 0.00% 0.00% 0.00% 0.00% 0.00%
scheduler 12.83% 0.18% 1.69% 0.44% 0.00%
Thread other port send sleep timers
async 0.00% 0.00% 0.00% 100.00% 0.00%
aux 0.00% 0.00% 0.00% 99.90% 0.00%
dirty_cpu_sche 0.00% 0.00% 0.00% 99.99% 0.00%
dirty_io_sched 0.00% 0.00% 0.00% 100.00% 0.00%
poll 0.00% 0.00% 0.00% 78.52% 0.00%
scheduler 4.25% 4.25% 0.64% 2.21% 0.48%
These stats reveal that the two most utilized thread types are poll and scheduler. The poll threads are 78% idle and 19% checking IO state. The scheduler threads spend 12% in the emulator (running code) and 56% in busy waiting.
Our theory is confirmed: true utilization is in fact lower than CPU utilization reported by the OS.
Another side effects of the busy wait approach occurs when the machine is not fully dedicated to running BEAM.
In this case, other (non-BEAM) kernel threads may receive an unfairly low slice of CPU time. In addition, when running BEAM in the cloud on burstable performance instances, busy waiting may result in spending unnecessary CPU credits.
To alleviate this, the BEAM virtual machine has a set of options that regulate the amount of busy waiting done by the VM. These options are +sbwt, +sbwtdcpu, and +sbwtdio. When set to none they disable busy waiting in the main schedulers, dirty CPU schedulers, and dirty IO schedulers, respectively.
The important question is whether there is any effect on responsiveness if busy waiting is disabled. To find out, we ran a test for the limited use case of serving HTTP requests with the Cowboy web server.
The Test
To run the test, we used the Stressgrid load-testing framework with 10 c5.2xlrage generators. Stressgrid monitors CPU utilization of the generators, so we can avoid skewed results due to generator oversaturation. In our test, all generators stayed below 80% CPU utilization.
We used a synthetic workload consisting of 100k client devices. Each client device opens a connection and sends 100 requests with 900±5% milliseconds in between each one. The server handles a request by sleeping for 100±5% milliseconds, to simulate a backend database request, and then returns 1 kB of payload. Without additional delays, this results in the average connection lifetime of 100 seconds, and the average load of 100k request per second.
In order to compare BEAM behavior in different conditions, we ran our test against c5.9xlarge, c5.4xlarge, and c5.2xlarge target EC2 instances. We chose these instance types with the following assumptions:
c5.9xlarge would allow for meaningful headroom of CPU capacity, to let the virtual machine run without any stress;
On c5.4xlarge, the virtual machine would nearly exceed CPU capacity;
c5.2xlarge would not have sufficient CPU capacity to handle the workload, causing the virtual machine to run under stress.
With each instance type, we ran the test with and without busy waiting. To disable busy waiting, we added the following lines to vm.args:
+sbwt none
+sbwtdcpu none
+sbwtdio none
Looking at requests per second, we see that c5.9xlarge and c5.4xlarge handle the full target workload of 100k requests per second and that c5.2xlarge does not, becoming saturated at 58k requests per second. Busy wait settings have no effect for this metric.
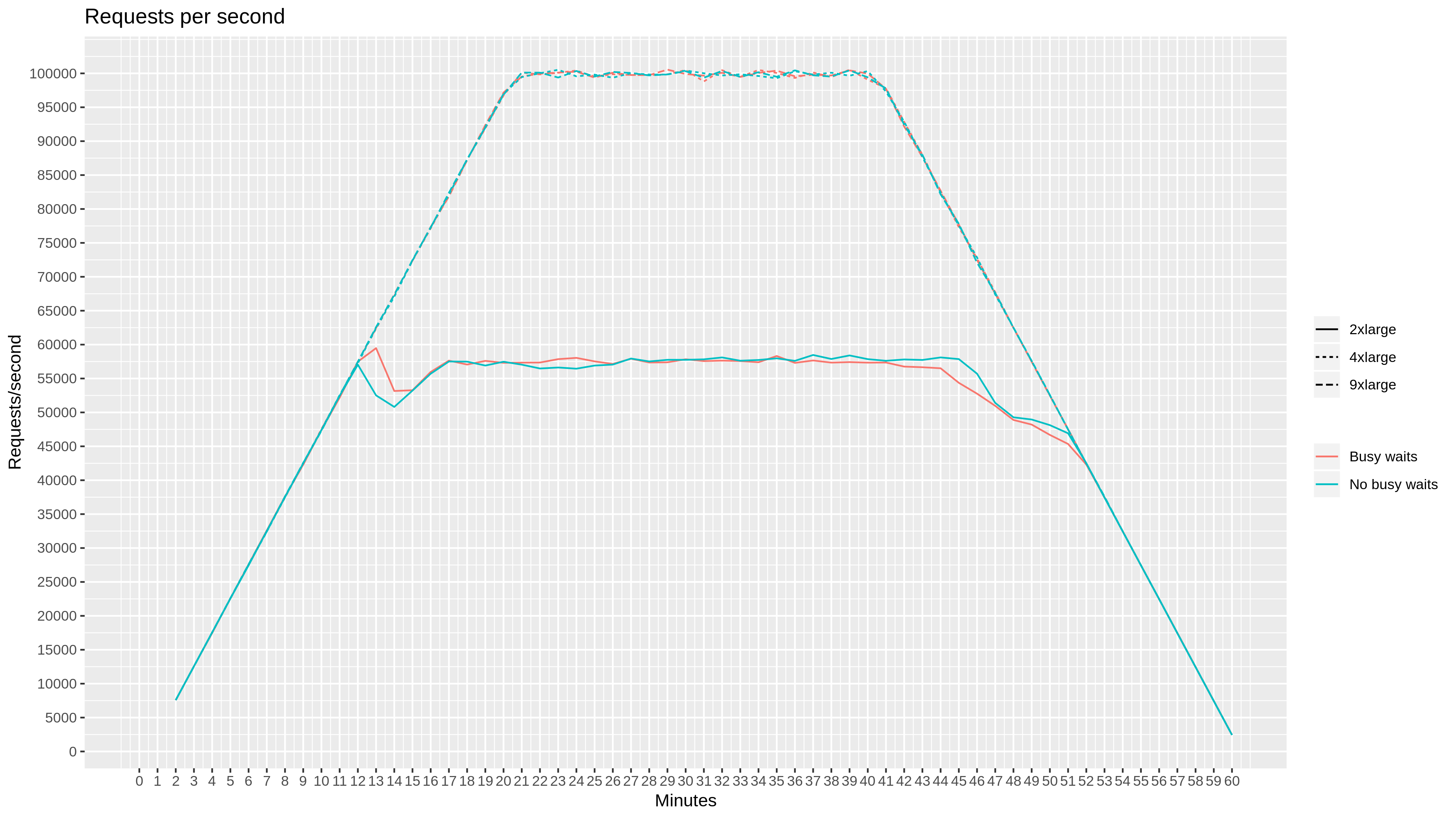
On the other hand, busy wait settings show a very significant impact on CPU utilization graphs. For all instance types, enabling busy waiting causes the CPU to be saturated above 95%. Disabling busy waiting causes CPU utilization to scale with the workload.

To get a more detailed picture, we also collected two latency metrics, along with the corresponding distribution characteristics: the time to open a connection and the time to HTTP response headers.
Again, c5.9xlarge and c5.4xlarge instances show similar results in responsiveness, and no meaningful difference with respect to busy wait settings.
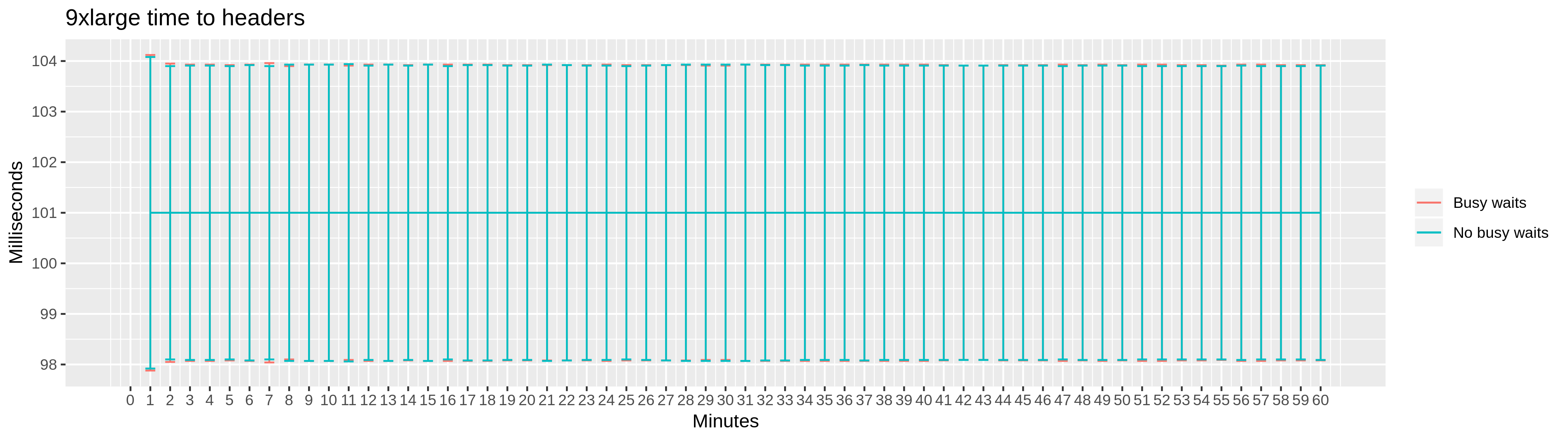
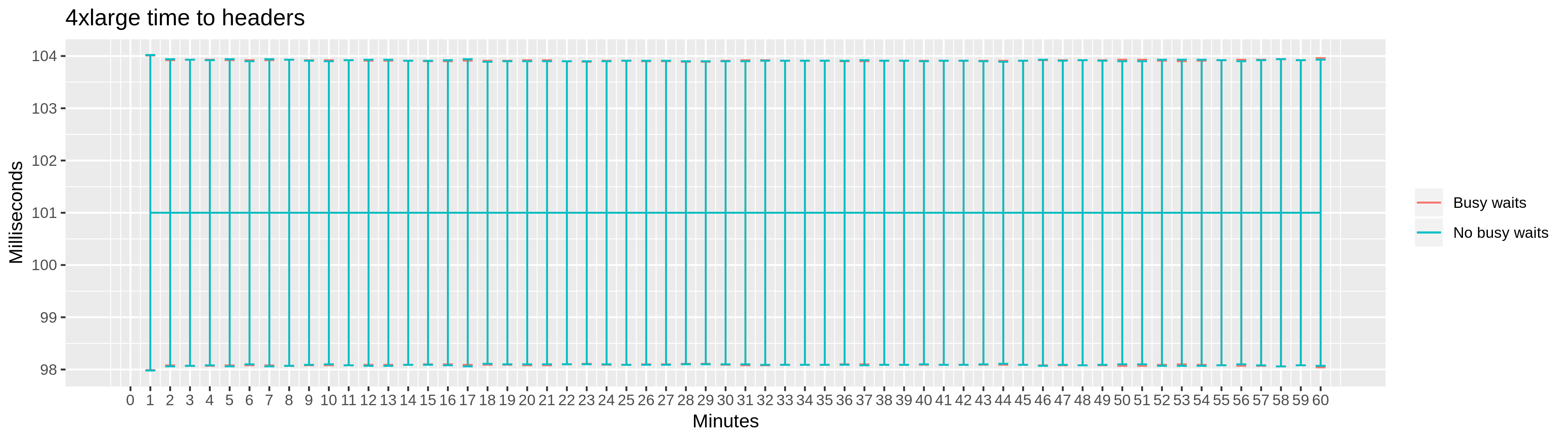


The latency metrics collected for the c5.2xlarge instance confirm the BEAM virtual machine working under stress, with latencies and standard errors increasing. Yet again, we see no meaningful difference between enabled and disabled busy waiting.


Conclusion
In our test, we found that BEAM’s busy wait settings do have a significant impact on CPU usage.
The highest impact was observed on the instance with the most available CPU capacity. At the same time, we did not observe any meaningful difference in performance between VMs with busy waiting enabled and disabled.
We must note that our use case was limited to serving HTTP requests with the Cowboy web server, and it is conceivable that in a different scenario there would be a noticeable difference. After all, this is probably why busy waiting was introduced to BEAM in the first place.
When running HTTP workloads with Cowboy on dedicated hardware, it would make sense to leave the default—busy waiting enabled—in place. When running BEAM on an OS kernel shared with other software, it makes sense to turn off busy waiting, to avoid stealing time from non-BEAM processes.
It would also make sense to not use busy waiting when running on burstable performance instances in the cloud.